PDF on the Web: Then and Now
In 2001 Jakob Nielsen warned about using pdf on the web in his famous article “PDF: Unfit for Human Consumption”. He said: “Forcing users to browse PDF files makes usability approximately 300% worse compared to HTML pages. Only use PDF for documents that users are likely to print.”
Fast forward 18 years.... contrary to Nielsen's advice, PDF didn’t vanish when users printed less; quite the opposite. We encounter more PDFs on the web than ever before and the number continues to grow. Nowadays we see a coexistence between PDF and HTML. The current status is a result of several changes:
- Adobe gave the PDF specification to ISO and the format matured. PDF/A, PDF/X, PDF/UA, are now widely accepted as de facto standards for archiving, digital publishing and document accessibility. PDF is not about “printing” anymore.
- The web is different too, far beyond the changes in HTML5. Today, more than 50% of web traffic is from mobile devices, applications are moving to clouds, websites are more powerful, interactive and responsive. Increasingly, for end users, browsers are “the only application needed”.
Have users stopped hating the PDF format? Or have they just accepted it as a necessary evil? Or is pdf actually kind of cool? A bit of everything in my opinion.
PDF today
Today, PDF viewing capabilities are an essential part of any operating system (even on mobile devices); indeed, all modern web browsers offer built-in PDF viewers. The days of the “Reader plugin” are gone. Digital document formats, PDF in particular, are at the centre of digital transformation, with vendors offering specialized workflows for collaboration, archiving, signing, indexing, searching, encryption, redaction and many more. Far from being a printing solution, PDF is a core technology of the online world.
So are we good now? No, not really. Usability isn’t perfect. Typically, neither the author of the document or manager of the website can control the way pdf is consumed by the end user. Each browser treats PDF files differently; PDF isn’t part of the HTML language. That makes it hard to incorporate into the expected user experience on the web. And despite all attempts, HTML (compared to PDF) doesn’t have good answers to problems such as packaging, archiving, reliability, authenticity, redaction, annotation and more. So HTML and PDF are in a situation of a married couple where both partners have their own interests and everybody accepts that because they are trying to be nice to each other.
The question is how can we get them to play better together? Is that even possible? A few years ago the PDF Association formed a technical working group to discuss and study ways in which PDF content could be effectively reused in various scenarios. We recently announced the first result of our work in a form of a derivation algorithm, a document describing the process of producing conforming HTML from a tagged PDF. I’m here to explain what are we up to.
Deriving HTML from PDF: the basic concept
Traditional PDF files can only be deterministically rendered. With precision, we draw element after element on the canvas. Properties of the rendering like colour, font, opacity etc. are defined by graphic state and position by basic math operations.
PDF authors can enrich the document with structural information. The author decides that a specific chunk of text is a paragraph, or a cell in a table.
 The concept of tagging PDF content isn’t new; it’s the cornerstone of accessible PDF files. Assistive technologies such as screen readers interpret document content based on the structure tree. But with new language introduced in PDF 2.0 authors can take full control over deriving PDF into HTML or any other structured format.
The concept of tagging PDF content isn’t new; it’s the cornerstone of accessible PDF files. Assistive technologies such as screen readers interpret document content based on the structure tree. But with new language introduced in PDF 2.0 authors can take full control over deriving PDF into HTML or any other structured format.
The derivation algorithm detailed in “Deriving HTML from PDF” basically describes the mapping of PDF tags (PDF calls them structure elements) into HTML tags. Both tag-sets are not equivalent, which is natural, due to specific features of both languages. The algorithm precisely describes all the differences and edge cases so the resulting HTML is always valid and represents the best possible translation of the author’s intent.
The PDF language can carry information about styling through structure attributes or associated files. The document can serve as a guide for embedding such information into tagged PDF files.
Text elements marked with a paragraph structure element in a PDF can freely be interpreted as a reflowable paragraph in HTML without compromising the message author wanted to deliver, delivering the content the way the author intended.
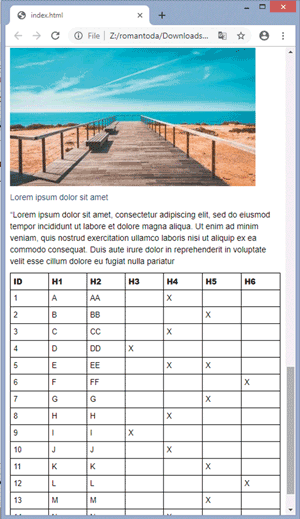 Conclusion
Conclusion
Tagged PDF is the way to generate reusable PDF documents, allowing the author to control the experience even in different environments.
Users who simply print to PDF are throwing away important information about headings, columns, reading order, etc that could be leveraged by downstream applications.
That’s my main message here: it’s becoming expensive to create PDF documents cheaply.
Are you interested in reusable PDF? Simply download Deriving HTML from PDF, join the Next-generation PDF Technical Working Group and help drive this initiative!
Check out Normex’s initial implementation on GitHub and our handcrafted pdf files to see the power of the algorithm and PDF language on real samples. And watch this space - we are developing articles to explain the technical details of the whole concept.
Roman Toda, Normex, is first and foremost a software developer. C++ expert with more than 20 years of experience with PDF. He’s been developing all major PDF features in high quality PDF libraries and products like encryption, digital signatures, export and import, data extraction, low and high level PDF editing, rendering, forms, XFA, annotations, scanning & OCR. Technologist and team leader able …
This article first appeared at https://www.pdfa.org/pdf-on-the-web-then-and-now/