How to Build a Knowledge Graph in Four Steps: The Roadmap From Metadata to AI
The scale and speed at which data and information is being generated today makes it challenging for organizations to effectively capture valuable insights from massive amounts of information and diverse sources.
We rely on Google, Amazon, Alexa, and other chatbots because they help us find and act on information in the same way and manner that we typically think about things. As organizations explore the next generation of scalable data management approaches, leveraging advanced capabilities such as automation becomes a competitive advantage.
Think about the multiple times organizations have undergone robust technological transformations. Despite developing a business case, a strategy, and a long-term implementation roadmap, many often still fail to effect or embrace the change. The most common challenges we see facing the enterprise in this space today include:
- Limited understanding of the business application and use cases to define a clear vision and strategy.
- Not knowing where to start, in terms of selecting the most relevant and cost-effective business use case(s) as well as supportive business or functional teams to support rapid validations.
- There are multiple initiatives across the organization that are not streamlined or optimized for the enterprise.
- Enterprise data and information is disparate, redundant, and not readily available for use.
- Lack of the required skill sets and training.
Our experience at Enterprise Knowledge demonstrates that most organizations are already either developing or leveraging some form of Artificial Intelligence (AI) capabilities to enhance their knowledge, data, and information management.
Commonly, these capabilities fall under existing functions or titles within the organization, such as data science or engineering, business analytics, information management, or data operations.
However, given the technological advancements and the increasing values of organizational knowledge and data in our work and the marketplace today, organizational leaders that treat their information and data as an asset and invest strategically to augment and optimize the same have already started reaping the benefits and having their staff focus on more value add tasks and contributing to complex analytical work to build the business.
The most pragmatic approaches for developing a tailored strategy and roadmap toward AI begin by looking at existing capabilities and foundational strengths in your data and information management practices, such as metadata, taxonomies, ontologies, and knowledge graphs, as these will serve as foundational pillars for AI.
Below, I share in detail a series of steps and successful approaches that will serve as key considerations for turning your information and data into foundational assets for the future of technology.
What is AI?
At EK, we see AI in the context of leveraging machines to imitate human behaviors and deliver organizational knowledge and information in real and actionable ways that closely align with the way we look for and process knowledge, data, and information.
What is a Knowledge Graph?
An Enterprise Knowledge Graph provides a representation of an organization’s knowledge, domain, and artefacts that is understood by both humans and machines. To this end, Knowledge Graphs serve as a foundational pillar for AI, and AI provides organizations with optimized solutions and approaches to achieve overarching business objectives, either through automation or through enhanced cognitive capabilities.
Getting Started…
Step 1: Identify Your Use Cases for Knowledge Graphs and AI?
As an enterprise considers undergoing critical transformations, it becomes evident that most of their efforts are usually competing for the same resources, priorities, and funds. Identifying a solid business case for knowledge graphs and AI efforts becomes the foundational starting point to gain support and buy-in.
Effective business applications and use cases are those that are driven by strategic goals, have defined business value either for a particular function or cross-functional team, and make processes or services more efficient and intelligent for the enterprise. Prioritization and selection of use cases should be driven by the foundational value proposition of the use-case for future implementations, technical and infrastructure complexity, stakeholder interest, and availability to support implementation.
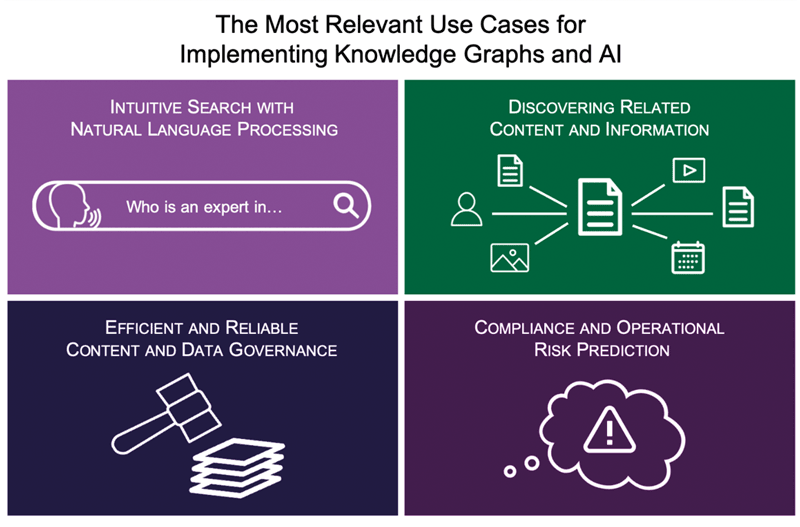
The most relevant use cases for implementing knowledge graphs and AI include:
- Intuitive search using natural language;
- Discovering related content and information, structured or unstructured;
- Reliable content and data governance;
- Compliance and operational risk prediction; etc.
For more information regarding the business case for AI and knowledge graphs, you can download our whitepaper that outlines the real-world business problems that we are able to tackle more efficiently by using knowledge graph data models.
Once your most relevant business question(s) or use cases have been prioritized and selected, you are now ready to move into the selection and organization of relevant data or content sources that are pertinent to provide an answer or solution to the business case.
Step 2: Inventory and Organize Relevant Data
The majority of the content that organizations work with is unstructured in the form of emails, articles, text files, presentations, etc. Taxonomy, metadata, and data catalogs allow for effective classification and categorization of both structured and unstructured information for the purposes of findability and discoverability.
Specifically, developing a business taxonomy provides structure to unstructured information and ensures that an organization can effectively capture, manage, and derive meaning from large amounts of content and information.
There are a few approaches for inventorying and organizing enterprise content and data. If you are faced with the challenging task of inventorying millions of content items, consider using tools to automate the process. A great starting place we recommend here would be to conduct user or Subject Matter Expert (SME) focused design sessions, coupled with bottom-up analysis of selected content, to determine which facets of content are important to your use case.
Taxonomies and metadata that are the most intuitive and close to business process and culture tend to facilitate faster and more useful terms to structure your content. Organizing your content and data in such a way gives your organization the stepping stone towards having information in machine readable format, laying the foundation for semantic models, such as ontologies, to understand and use the organizations vocabulary, and start mapping relationships to add context and meaning to disparate data.
Step 3: Map Relationships Across Your Data
Ontologies leverage taxonomies and metadata to provide the knowledge for how relationships and connections are to be made between information and data components (entities) across multiple data sources.
Ontology data models further enable us to map relationships in a single location at varying levels of detail and layers. This, in turn, sets the groundwork for more intelligent and efficient AI capabilities, such as text mining and identifying context-based recommendations. These relationship models further allow for:
- Increasing reuse of “hidden” and unknown information;
- Managing content more effectively;
- Optimizing search; and
- Creating relationships between disparate and distributed information items.
Tapping the power of ontologies to define the types of relationships and connections for your data provides the template to map your knowledge into your data and the blueprint needed to create a knowledge graph.
Step 4: Conduct a Proof of Concept – Add Knowledge to your Data Using a Graph Database
Because of their structure, knowledge graphs allow us to capture related data the way the human brain processes information through the lens of people, places, processes, and things.
Knowledge graphs, backed by a graph database and a linked data store, provide the platform required for storing, reasoning, inferring, and using data with structure and context. This plays a fundamental role in providing the architecture and data models that enable machine learning (ML) and other AI capabilities such as making inferences to generate new insights and to drive more efficient and intelligent data and information management solutions.
Start small. Conduct a proof of concept or a rapid prototype in a test environment based on the use cases selected/prioritized and the dataset or content source selected. This will give you the flexibility needed to iteratively validate the ontology model against real data/content, fine tune for tagging of internal & external sources to enhance your knowledge graph, deliver a working proof of concept, and continue to demonstrate the benefits while showing progress quickly.
Testing a knowledge graph model and a graph database within such a confined scope will enable your organization to gain perspective on value and complexity before investing big.
This approach will position you to adjust and incrementally add more use cases to reach a larger audience across functions. As you continue to enhance and expand your knowledge across your content and data, you are layering the flexibility to add on more advanced features and intuitive solutions such as semantic search including natural language processing (NLP), chatbots, and voice assistants getting your enterprise closer to a Google and Amazon-like experience.
Ready for AI? Automate, Optimize, and Scale.
Core AI features, such as ML, NLP, predictive analytics, inference, etc., lend themselves to robust information and data management capabilities. There is a mutual relationship between having quality content/data and AI.
The cleaner and more optimized that our data, is the easier it is for AI to leverage that data and, in turn, help the organization get the most value out of it. Within the context of information and data management, AI provides the organization with the most efficient and intelligent business applications and values that include:
- Semantic search that provides flexible and faster access to your data through the ability to use natural language to query massive amounts of both unstructured and structured content. Leveraging auto-tagging, categorization, and clustering capabilities further enables continuous enhancement and governance of taxonomies/ontologies and knowledge graphs.
- Discover hidden facts and relationships based on patterns and inferences that allow for large scale analysis and identification of related topics and things.
- Optimize data management and governance through machine-trained workflows, data quality checks, security, and tracking.
Organizations that approach large initiatives toward AI with small (one or two) use cases, and iteratively prototype to make adjustments, tend to deliver value incrementally and continue to garner support throughout. The components that go into achieving this organizational maturity also require sustainable efficiency and show continuous value to scale.
As your organization is looking to invest in a new and robust set of tools, the most fundamental evaluation question now becomes ensuring the tool will be able to make extensive use of AI.
If you are exploring pragmatic ways to benefit from knowledge graphs and AI within your organization, we can help you bring proven experience and tested approaches to realize and embrace their values.
 Lulit Tesfaye is Practice Lead, Data & Information Management | Knowledge Graphs | Semantic AI at consulting firm Enterprise Knowledge.
Lulit Tesfaye is Practice Lead, Data & Information Management | Knowledge Graphs | Semantic AI at consulting firm Enterprise Knowledge.
https://enterprise-knowledge.com/