

All Intelligent Document Processing begins with a document - a collection of one or more pages. Pages form the basis of all the processing that the IDP platforms perform to make sense of data. Though most of the focus of ‘intelligence’ in IDP refers to how you make sense of data, you will be surprised how much Intelligence is used on a page before it is ready for data extraction.
I am not talking about things to do with scan quality such as your skew correction, resolution improvements or shadow removal, etc. I am talking about things to do with the basic anatomy of a page. Stuff that begs the question, “What is a page, anyway?”
A page is a page but it can get tricky. People who handle pages physically know what I am referring to. Sometimes, a single page can have multiple pages on it; sometimes, multiple pages have a single information unit spread on it; at times, you bump into filler pages or pages show up blank; sometimes random pages are put together in a 1,000 page document. Let’s look at the nuances of each scenario.
Multiple ‘pages’ on a single page
You just got back from a short business trip and now you need to file your expenses. You have a coffee receipt, a taxi bill, a dinner receipt, and a boarding pass. Instead of taking individual pictures of all of these, you lay them out next to each other and take one picture.
You have now produced ‘a page’ for document processing. However, an IDP platform first needs to split this one page into 4 before it can move to the next step.
Here’s another example -- you have multiple assets: two cars and a bike that are insured with an insurance provider. When you get your proof of insurance, it lists all three collaterals on a single page. An IDP system first needs to split this one page into 3 collaterals and then process each of them separately.
Consider a bank statement -- if you have multiple accounts with a bank, the summary page includes all of your accounts along with their balance on a single page. IDP systems need to treat these as separate accounts and extract information from each individual account.
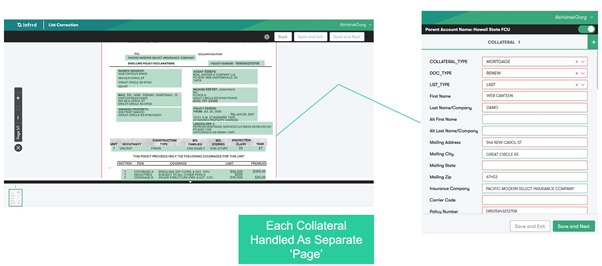
To process these kinds of pages, your IDP system needs to have the intelligence to split a single page into multiple pages and then process them for you. Our page segmentation model handles these documents using a combination of state-of-the-art computer vision, natural language processing (NLP), and predictive analytics algorithms.
The March of the Pages
The second pattern that we see a lot for large mailroom processing operations is that all the documents received in a day are scanned together into one giant document that is a few thousand pages long. It makes the whole operation very efficient and saves a lot of time required to sort each document.
Before the IDP platform can pick this up, it needs to understand where one document ends and a new one starts. In the past, vendors would have to ask customers to insert a blank page between every document within this giant scanned file. Today, we use our Page Continuity model to figure this out and automatically split a 1,000 page document into 200 documents.
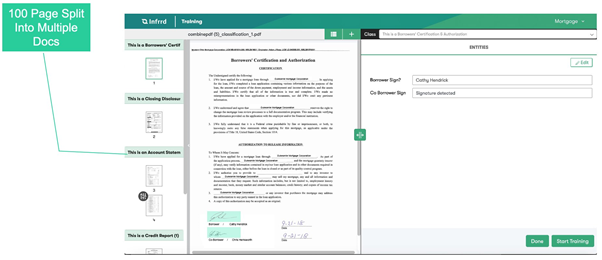
Once that is done, we use our Intelligent Classification model to figure out that pages 1-3 are part of a single invoice, pages 4-5 are also another invoice but a new one, page 6 has multiple receipts on a single page, and so on. Once the documents are split and understood, they are routed to the right extraction models and appropriate data processing teams for review and corrections.
Multiple Pages That Make a Single Page
When processing visual information elements such as tables, we come across information that spans multiple pages. In this case, the IDP system needs to form a composite page from multiple pages and then extract information as a single information unit. Our page stitching models process these pages, remove information repeated on multiple pages, and form a single object for extraction.
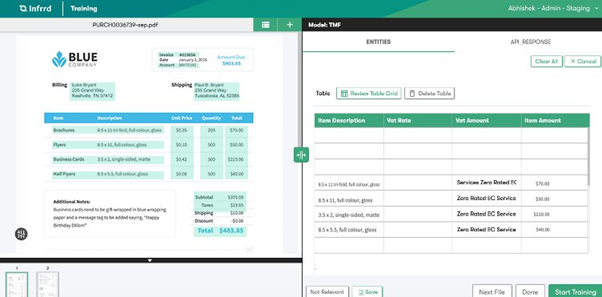
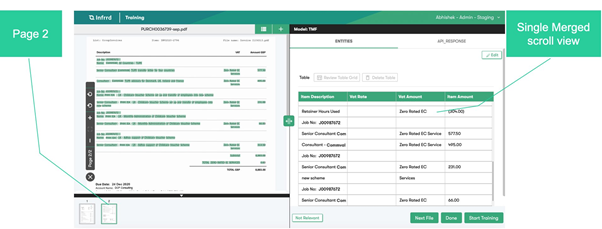
Blank Page
And of course, sometimes you come across a blank page in a document that does not add any value to extraction. These pages need to be removed from the documents for processing. We do this using our blank page detection model.
So, What is a Page?
As you can see, a page is not really a page. It can be multiple pages disguised as one page or one page that should have been multiple pages. It can also be a group of random, unrelated pages grouped together for convenience.
Your IDP system needs to have the right intelligence to efficiently handle these scenarios, to ensure you do not waste time in managing tasks that AI can automate for you.