
Organsations habitually over-retain information, especially unstructured electronic information, for many reasons. However, many organisations simply have not addressed what to do with this data so fall back on relying on individual employees to decide what should be kept and for how long and what should be disposed of.
On the opposite end of the grey data management spectrum, a minority of organisations have tried centralised enterprise content management systems and have found them to be difficult to use. In these cases, employees find ways around these complex systems by keeping huge amounts of data locally on their workstations, on enterprise file shares, on removable media, in cloud accounts, or on rogue SharePoint sites that are used as “data dumps” with little or no records management or IT supervision.
Much of this information is transitory, expired, or of questionable business value. Because of this lack of active management, information continues to accumulate. This information build-up raises the cost of storage as well as the risk associated with ediscovery. In some cases, the company’s General Counsel actively stops grey data “clean up” processes because they are afraid of being accused of destruction of evidence in a future case.
The lifecycle of information – active to grey data
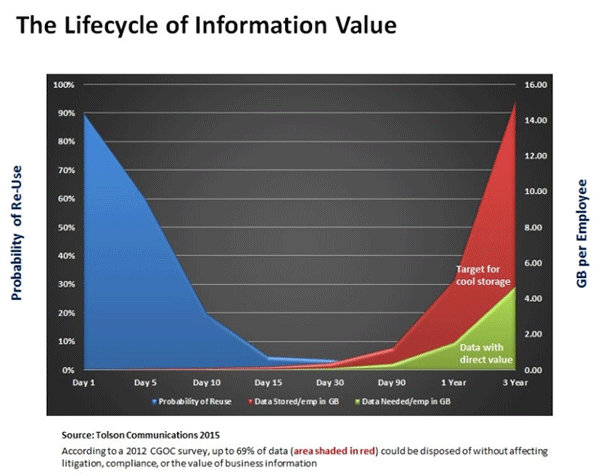
Fred Moore, Founder of Horison Information Strategies, wrote about the concept of the lifecycle of information years ago. His theory was as information ages, it probability of re-use and therefore its value, shrinks rapidly. Once data has aged 15 to 30 days, its probability of ever being looked at again approaches 1%, and as it continues to age, approaches but never quite reaches zero.
Contrast that with the possibility that a large part of any organisational data store has little of no business, legal or regulatory value. In fact, the Compliance, Governance and Oversight Counsel (CGOC) conducted a survey in 2012 that showed that on the average, 1% of organizational data is subject to litigation hold, 5% is subject to regulatory retention and 25% had some business value.
This means that approximately 69% of an organisation’s electronic data store has little or no business value and could be disposed of if your legal department approved the disposal. But in reality, legal departments are extremely hesitant to actually delete data – afraid they will be seen as destroying evidence if a future lawsuit arises. So this huge amount of grey data continues to clog up expensive enterprise storage resources.
The real numbers
The average employee creates, sends, receives, and stores conservatively 20MB of data per day. This means that at the end of 15 business days, they have accumulated 220MB of new data, at the end of 90 days, 1.26GB of data and at the end of three years, 15.12GB of data.
So how much of this accumulated data needs to be retained and managed? Referring to figure 1 below, the red shaded area represents the information that probably has no legal, regulatory or business value according to the 2012 CGOC survey. At the end of three years, the amount of retained data from a single employee that could be managed more cost effectively without adverse effects to the organization is 10.43 GB. Now multiply that by the total number of employees and you are looking at some very large potential cost savings.
If companies could effectively capture and manage this grey data centrally utilising a low cost cloud repository, the company’s overall data costs as well as the cost to conduct ediscovery could be dramatically reduced.
As unstructured data volumes continue to grow, more cost-effective storage solutions need to be found for that low touch grey data that has a very low probability of reuse. Fortunately, new cloud storage solutions that utilise “cool” storage designs can drive your overall storage and ediscovery costs down for a while, ensuring your ability to effectively search and manage that information during its lifetime.
Microsoft Azure is that low cost cool data repository. Archive360’s Archive2Azure provides the management layer for Azure to allow this grey data to be migrated into Azure, encrypted, retention/disposition applied, and custom indexing processes enabled to provide centralised ultra-low-cost “cool” storage so that grey, low touch data can be managed and searched quickly.
Bill Tolson is Vice President of Marketing at Archive360, Inc. http://www.archive360.com/