
Since the inception of the home printer, one question has bewildered humanity: How do you predict the point at which the quality of the printed page will decline to such a degree that any residual ink in the cartridge isn’t worth extracting? Or, to put it more simply, when should you replace the ink, and thus, when do you need to buy more ink?
Today, the most modern printers can order toner when the levels are low. You don’t need to predict it. You don’t need to have excess on hand just in case. You don’t even need to click an order button.
Apply the same concept to an entire production line. A manufacturer’s production equipment is equipped with sensors that predict when a piece of machinery will need to go offline for maintenance. That means fewer man-hours for inspections, less premature maintenance, less overdue maintenance and less downtime.
Procurement can help limit that downtime by ordering parts and supplies in advance, optimizing to minimize the risk of being caught short with the expenses associated with inventory.
This is possible because of machine data, which is exactly what it sounds like: data produced by machines doing their jobs. Right now, your home internet modem is producing data by the millisecond. Your car produces and stores data. Your Alexa generates its own data, and it records the data you create when it’s listening in, which is all the time. Imagine the sheer volume of data your household devices produce every day, and then imagine how much your organization’s devices produce every hour.
Data in the Dark
This has created a problem people in tech call dark data: all the data an organization has but doesn’t know it has plus all the data a company knows it has but isn’t able to leverage. Two-thirds of IT and business leaders told data analytics platform provider Splunk that half or more of their organization’s data is dark. Why? Because of the sheer volume of data compounded by other factors such as legacy devices that weren’t designed with data collection and analytics in mind. All that data is lost value and opportunity.
Think again about that piece of production equipment able to predict its maintenance needs. If that equipment is connected to a purchasing system, not only can it predict when it will need maintenance, it can order the supplies itself. That’s known as a machine customer, which have existed for a while but are still in their infancy.
They’re a form of robotic process automation driven by the Internet of Things. Theoretically, that purchasing system could utilise artificial intelligence to compare suppliers and make a selection optimising cost, speed and whatever other factors supply chain wants to include in that decision.
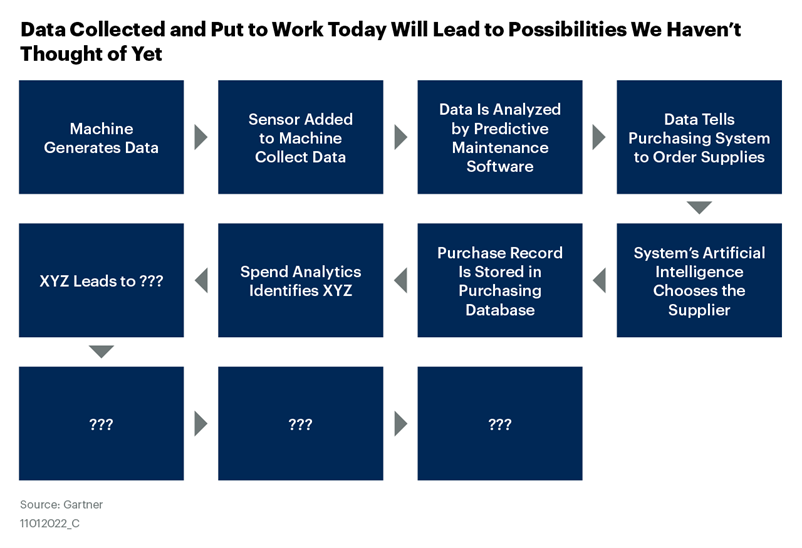
When that machine makes the purchase, the record and associated metadata would be entered alongside data from human-initiated purchases in your purchasing platform. Future spend analysis may need to account for distinctions between human versus machine purchases, human versus machine vendor selection, etc.
That spend analysis could lead to who knows what changes in purchasing, contract management, inventory control, and so on. The only limits are (1) how data generated by different activities are pooled to enable different analyses and (2) whether that data has been captured to be analysed at all.
Ask New Questions
What does this mean for supply chain leaders? The analytics in data analytics gets all the glamour. We naturally think of the questions that analysis can answer, but our imaginations tend to be limited by what we can see. We can see the data we have, so we ask questions of, and about, that data and make plans for what we’ll do with the answers.
Data collection, though, gets scant attention, not just in supply chain but across functions and industries. Supply chain needs to get in the habit of asking some new questions of itself and especially of its partners in the business, where the vast majority of data is generated:
- What data are we generating?
- What data are we collecting?
- What are we doing with the data we have?
- What could we do with our dark data if only we could capture it?
The more accurate the assessment, the better supply chain leaders will be able to answer questions they’re already asking all the time:
- How do we get the most ROI out of the technology we have?
- What should our technology roadmap look like?
- What should our technology strategy be?
This last question benefits especially from a more thorough accounting of what data the organization has at its disposal. Strategy is the coordination of the ends and the means, a plan for how you use what you have to achieve what you want.
Data is a means, and the lack of visibility into what data exists limits what we perceive as possible and leads to missed opportunities to more easily achieve and capitalize on those possibilities. Supply chain may not be able to solve the dark data problem, but it can prod those who can to make sure its own capabilities take the best possible advantage of their organization’s data assets in its digitization journey.
Ryan Tandler is Director, Research, Gartner Supply Chain