Developing a Legal Risk Model for Big Volumes of Unstructured Data
A not-so-hidden secret in information management is the out-of-control growth of unstructured data in corporate life. Millions of data files are stashed in loosely tracked and managed sources such as email, social media sites, and SharePoint, and the contents of these massive repositories are often poorly managed and understood. Unstructured data accounts for 90 percent of the digital universe, according to IDC, which estimates that these files are growing at a rate of 50 percent per year.
In 2011, IDC noted that the amount of information created and replicated will surpass 1.8 zettabytes (1.8 trillion gigabytes). In addition to a huge investment in data storage costs, companies also risk the expense of searching them all should they become subject to litigation.
(Re[rinted with permission from Data Informed)
Most companies have hung onto huge volumes of data, in part because they are worried about pitching something that might be valuable, but mostly because it seems like an overwhelming task to separate the wheat from the chaff. This problem can be solved in a rational, intelligent manner by developing a risk model to determine how to appropriately manage unstructured data. Using the right tools, and with the right approach, companies can limit their exposure to the legal and financial risks. - See more at:
Any piece of data outside of a formal database is “unstructured.” That includes data stored on a shared hard drive, within email, on corporate social media accounts, on devices such as phones and laptops, and more recently, within collaborative tools such as SharePoint sites. It’s impossible to quantify the number of SharePoint sites that have been created since the tool’s launch in 2001, but in working at my information governance consulting firm, we find that it’s not unusual for a company to have upwards of five active SharePoint sites per employee.
Company size is less the driver for more sites than company policy: those who allow employees to create a new SharePoint site without first securing IT approval tend to have the highest ratio per employee. In our work, we have seen a 2,000-employee company with 20,000 active SharePoint sites, and a 10,000-employee company with more than 50,000 sites. These sites are usually loosely regulated, if at all, and companies not only can’t quantify the number, they have no insight into their contents. The total dollar amount may be less for a small firm, but the financial burden is proportional: the inability to understand and manage data is costly for all.
Volumes have been written about how to establish some sort of oversight on this Wild West of data. That advice is helpful for managing incoming mounds of unstructured data. But most companies already have a huge mess on their hands.
Who Cares How Much Data We Keep, Anyway?
Most companies hate to throw data away. This is not a new phenomenon – storage facilities containing boxes of paper files “that we might need someday” occupy tens of thousands of acres. But electronic data can be easier to ignore, and many companies have opted to rent the electronic equivalent of a storage facility rather than weed out the junk. But electronic data is growing at exponential rates—upwards of 40 percent per year with many of our clients—and it builds to the point where the volume is overwhelming. It also carries a big price: Gartner estimates that it costs $5 million per year to store and manage a petabyte of information.
Unfortunately, mass-deleting information carries cost as well, including the loss of data that might be important to the business, and the risk of deleting information required for regulatory compliance.
But perhaps the biggest cost of unidentified data comes when a company must pay to categorize data as part of a legal electronic discovery process. Opposing attorneys can—and will—force companies to produce every piece of data that might be relevant to the case. The RAND Corporation put a number on that process of producing electronic discovery: approximately $940 per gigabyte to collect the data, $US2,931 per gigabyte to process it, and $US13,636 to review it, including fees and expenses for legal counsel.
The bottom line: you’re damned if you delete information, and damned if you don’t. And it is sheer fantasy to think that any organization has the time or resources to make granular, file-by-file decisions to categorize hundreds of millions of data objects. As Robert Kugel, a research director at Ventana Research notes, the only way to tackle this problem is through an analytical and risk management decision approach: “Relatively few companies have the resources to devote to comprehensively managing document retention,” Kugel says. “To address the practical issues that arise in deciding what to keep and what to destroy, they should consider an analytics-based approach to optimize their document-retention process.”
How a Risk Model Works
Making any decisions about data will involve risk—the goal is to minimize the impact. A multidimensional risk model can calculate the upside and downside risks of keeping versus deleting data. The process consists of a review a sample of the contents in each data repository, and based upon its characteristics, make a prediction about what the rest of the repository contains.
For example, a SharePoint site might contain HR files, marketing documents, scientific sample data, inventory, or accounting data. By knowing what kind of records the repository contains in relation to the business and industry, it is possible to gauge the potential value in multiple dimensions, issues including: business value, regulatory compliance value, historical/archival value, and litigation value.
For example, a repository that contains scans of all ads the company has created since its founding in the 18th century has little or no regulatory compliance value, but a very high historical or archival value. A SharePoint site of expense reimbursement policy documents has no real archival or regulatory compliance value, but might be used to defend against a future lawsuit.
The goal is to calculate the value for each dimension for the entire repository. Some repositories will be easy to put in buckets—HR and accounts payable, for example—and some will be unknown. The more repositories that can be categorized and valued, the more rational and effective the “keep-or-purge” decision process can be. Categorization also enables companies to calculate a risk value for each dataset across multiple scenarios, including for the business, in regards to regulatory compliance issues, for archival/historical purposes, or in terms of potential litigation.
An Example of the “Keep Versus Purge” Decision
Following is an example of the process that my firm conducted for a corporation in a heavily regulated industry with a dataset containing approximately 250,000 objects, in varying states of organization and indexing quality. The task was to provide a rational way to make decisions on how to manage the data; the outcome was a model to assess the risk for keeping versus purging each set and subset of data.
The first dimension was to quantify what was known about the data, grouping sets into categories loosely defined as “we know a lot,” “we know some,” and “we don’t know anything.” Each category and sub category required its own risk assessment.
The next dimension was to evaluate the datasets in terms of the regulatory climate. This corporation was in an industry regulated by a large array of laws—a known set of values, any of which could potentially apply to items within the dataset—an unknown value. Again, each category of data was assessed for its potential regulatory risk, with multiple scenarios for high, medium, and low probability of applicability.
A third dimension was the dollar value of potential regulatory or legal actions. Because there were a large number of laws that could apply to the data, the risk of making a bad decision impacting a regulatory issue was increased. With the wrong outcome, a court case, fines, or criminal action would carry a very high dollar value. This industry had received prominent attention from the media, only increasing the risk factors.
The risk model incorporated these three dimensions—data identification, regulation applied to the industry, and the dollar value of the downside risks. The model included numerous subcategories for each of these dimensions, including specific legal regulations and the dollar penalties associated with them, enabling the corporation to make keep-or-delete decisions that were based on something akin to an actuarial calculation—in essence, the assumed liability of any action. The corporation used the model to determine the potential cost of the risk for each subcategory of data. The model was granular enough so that the corporation could calculate the costs for multiple scenarios, including what it would cost to research the contents of each unknown dataset, what it would cost to prepare for and litigate potential court cases, and what it could cost in terms of potential fines. Establishing the price tag for each scenario enabled the corporation to make a rational decision on what to do with those 250,000 data objects.
Using Technology to Manage Interrelationships
Assessing risk in repositories of this size is particularly challenging because each piece of data carries not only its own value, but also its value in relation to other data in the organization.
Consider: Each piece of data a company store is interconnected with many others, and the value of each is interconnected to its risk: while eliminating a data repository might have a very low risk in terms of regulatory compliance, it might have a very high risk in terms of value to the business. A SharePoint site might carry a low archival value, but a high risk for litigation. There are any number of combinations, which is where technology comes into play—modeling tools can manage these complex, multidimensional relationships within the dataset and within the risk landscape.
Tools such as spreadsheets are inadequate for such a modeling process—they simply lack the sophistication and horsepower necessary for this sort of analysis. Our firm uses multidimensional modeling software to develop risk models that enable companies to manage this complex process with a high degree of confidence. These multidimensional risk models can map a large number of factors against each other, measure the interrelationships, and develop numerous scenarios to assess the risk of keeping or discarding various data. The more sophisticated the mapping, the better the ability to gauge risk and make rational decisions. (See “Examples of Two Risk Analysis Models,” below.)
A Strong Risk Model Is a Good Defense
This type of risk model also helps corporations defend decision-making in court and reduce liability. Opposing attorneys increasingly are accusing companies of spoliation, which is the intentional or negligent withholding, hiding, altering, or destroying of evidence relevant to a legal proceeding. Opposing attorneys can and do make broad, sweeping demands for information, and try to exploit any gaps—real or perceived—in order to make their case against a company. In order to test that assertion, a judge will want to see some evidence of what was deleted, and why. The company’s records retention policies and procedures, and the implementation of them, will therefore be implicated. Companies must document repositories kept, repositories deleted, and the process used to make the determination—all supported by the data contained in a comprehensive risk model.
Developing a risk model requires creating a data hierarchy, and assigning risk and value to each group and subgroup based upon specific industry parameters. Whether companies do it internally or bring in an expert, they must use technology that can capture the multidimensional interrelationships among all of the data, and ease the process of assigning risk and value. Developing a comprehensive risk model is the first step toward freeing an organization from the overwhelming amount of data it should no longer have to carry.
Examples of Two Risk Analysis Models
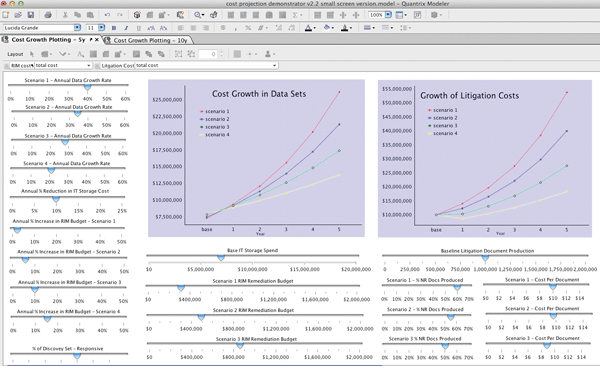
The image above is a detail taken from an illustration of a cost growth plotting model, a general analytical tool created using business modeling and analytics software Quantrix Modeler, and used by Montaña & Associates to help companies determine the cost of maintaining information.
The model contains “sliders” to gauge the impact of changes to a variety of metrics, including the growth of datasets, the decreasing cost of storage media, and the cost of data discovery. Changing these values enables the model to produce a number of scenarios, and determine the cost to generate various outcomes. Each variable is measured across a five-year period. The term RIM refers to records and information management; “NR doc” refers to non-responsive, or documents captured during a search that turn out to be irrelevant.
Another model developed using the Quantrix software is a retention analysis model. This model groups various datasets together to calculate risks. Decisions on how data are grouped impact outcomes: moving one set of records can impact the risk value for each category. The challenge for information managers is to determine the optimal way to group data.
This model helps companies understand the impact by mapping that information in a spreadsheet-like display: The rows represent the types of records a company has in its datasets such as accounts payable, accounts receivable, and others. The columns represent four areas of legal authority that should be tracked against each type of record—requirements, statutes of limitation, audit periods, and inspection cycles. Each legal category is displayed as a mean, median, mode, and standard deviation.
These statistical breakdowns enable a company to compare its organizational and governance schemes against those in an optimal model, and discover inefficiencies. A high deviation in any one area indicates outliers in the data, and can indicate that the organization, or grouping, of the data is not optimal. The further the deviation, the higher potential for cost of information management, and the higher the potential for risk. With this type of detailed model, companies can develop numerous scenarios and make decisions based on quantified outcomes.
 John Montaña is the principal at Montaña & Associates, a firm based in Landenberg, Pa., which provides independent consulting on information governance and records management. Contact him at jcmontana@montana-associates.com.
John Montaña is the principal at Montaña & Associates, a firm based in Landenberg, Pa., which provides independent consulting on information governance and records management. Contact him at jcmontana@montana-associates.com.
Copyright 2013 by Data Informed and Wellesley Information Services. Reprinted by permission of the publisher.