

Every year, companies face the inevitable prospect of adding additional terabytes of new storage resources to their numerous, overloaded, and expensive enterprise storage repositories to keep up with the constantly growing storage requirements. These storage repositories include application-specific repositories, on-premises email archives, department share drives, individual employee "home" drives, SAN/NAS devices, employee cloud accounts, SharePoint systems, to name just a few.
To help control the costs of the constantly expanding enterprise storage resources, companies previously installed stand-alone archives for each application to manage both structured and unstructured inactive data to ease data storage and management costs. Additionally, the archives ensured aging data was readily available for eDiscovery and regulatory information requests, analytics processes, and employee reference.
In the last several years, some information management solution vendors have begun promoting the idea of in-place or federated information management. This concept (as opposed to a centralized/consolidated strategy) is intended to fully manage your different file types from one main management application dashboard across multiple application repositories as well as numerous enterprise storage locations.
The overall goal is to simplify information management by providing in-place management capabilities that enable users to search for content using one search interface, no matter where it is stored in the enterprise, while providing centralized retention/disposition capabilities. In other words, in-place information management allows employees and applications to store files in their original repositories while providing an overall management structure.

Figure 1: Federated Information Management manages files via policies from a centralized dashboard. This allows centralized search of all connected repositories.
Active versus inactive files and storage costs
In-place information management makes sense for active files with a high probability of being used/referenced/shared regularly. But does it make sense for inactive or rarely accessed data?
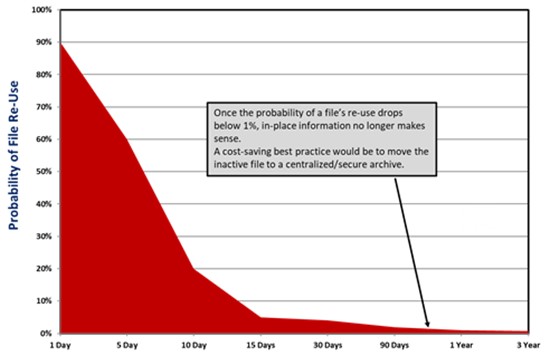
Figure 2: Most content rapidly becomes inactive. Once it reaches a very low probability of re-use, it makes much more sense to move the file to a lower-cost centralized archive.
The answer is almost always no.
Why? Application-specific enterprise repositories, on-premises email archives, department share drives, individual employee "home" drives, SAN/NAS devices, and SharePoint storage repositories are usually configured using tier 1 or 2 storage – the most expensive enterprise storage resources.
As I mentioned previously, an in-place information management approach for active data can be an effective tool. However, a strict delineation strategy should be created to automatically consolidate inactive data into a central repository employing tier 3 or 4 storage resources for ongoing management - including retention/disposition, security/privacy, employee access, regulatory compliance, eDiscovery, and analytics to take advantage of a much lower overall cost.
Managed files can quickly become inactive while still governed by a time-based retention policy. Most files, especially those retained for regulatory purposes, become inactive as soon as they are stored. As the probability of those files ever being viewed again drops below 1 percent (figure 2), the cost justification of keeping inactive files on expensive storage becomes difficult.
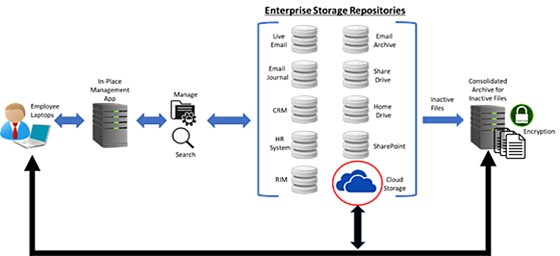
Figure 3: Moving inactive data to a centralized repository reduces storage cost while also providing higher data security.
In-place information management perpetuates higher eDiscovery costs
One obvious issue with in-place information management is that it does not address duplicate files stored in the various repositories, i.e., the same files stored in SharePoint, department file shares, home drives, employee clouds (OneDrive), etc. This practice ends up consuming more expensive enterprise storage.
However, the limitations of in-place information management go far beyond potential storage savings: duplicate files will drive up the cost of eDiscovery and regulatory response.
During the discovery phase of litigation, the responding party must search for and review all potentially relevant data to determine if it should be turned over to the requesting side.
Performing a discovery search of 5, 10, or more data repositories, even from a central dashboard, would turn up a large number of duplicate emails, work documents, regulated records, etc. All collected duplicate files would need to be reviewed by legally trained or contract review lawyers, driving up the cost of eDiscovery. The same holds for organizations responding to regulatory information requests.
The US Financial Services industry requires unique information capabilities
Companies in the US financial services industry are required to supply access of all compliance records to an external Designated Third-Party (D3P) based on SEC Rule 17a-4. This rule requires all broker-dealers to hire and retain a Designated Third Party, who would maintain independent access to the broker-dealer's SEC-regulated records. The rule requires the D3P can download all compliance records on behalf of the regulatory authority if the dealer is either not able or willing to comply with an audit or investigation.
For FinServ organizations employing an in-place records management strategy, the D3P would need to be given access to all corporate information systems that store regulated records. Compare that to a central archive where the broker/trader would only need to provide (audited) access to the centralized archive.
In fact, most FinServ companies rely on centralized information management and archiving solutions to ensure regulatory compliance and legal defensibility while ensuring the lowest total storage cost and highest data security.
Data security limitations of in-place information management
An important consideration for employing an in-place information management solution is that of data security. An in-place information management solution depends on the already existing enterprise (network) security resources already in place, i.e., firewalls, etc.
However, with the exploding and quickly evolving cyber and ransomware environment and the emerging privacy laws, an additional layer of data security should also be considered.
For example, targeted access controls, real-time auditing, sensitive data encryption, secure multiparty computation, and field-level encryption should be employed to reduce the risk of sensitive data theft through phishing, internal theft, and 2-stage extortionware. These new threats highlight the need for additional data security to protect your organization's sensitive data and not run afoul of the strict privacy regulations.
In the new ransomware environment, which now includes cyber-extortion - encrypting all sensitive and regulated records is considered a best practice. Cyber-extortion ransomware attacks now involve searching for and copying personal information and other sensitive data to the hacker's own servers.
They are later used to extort the victim organization into paying the ransom or, the sensitive data will be released to the dark web, which would trigger huge fines (usually much higher than the requested ransom) from the GDPR, CCPA/CPRA, and numerous other privacy laws around the world.
In-place data security relies on infrastructure security
Something to keep in mind; to date, in-place information management systems do not offer advanced data encryption needed to secure each file while also making it available for full search, ongoing management, and analytics.
In-place versus centralized archiving
In-place information management has its merits, as long as data that becomes inactive is automatically moved to a lower cost, centralized, and secure archiving platform. Otherwise, the budgetary, legal and security risks outweigh any potential benefits.
It comes down to one simple truth: fewer copies of inactive files in fewer places results in lower storage costs, higher levels of information security and privacy, faster and less costly eDiscovery. Plus, the ability to run analytics on a more comprehensive (both structured and unstructured) and analytically viable data set.
Archive360 is the world's leader in secure data migration and intelligent information archiving and management. The Archive2AzureM solution is a native cloud-based information management and archiving solution for both structured and unstructured data, which is installed in your company's Azure Cloud tenancy for increased security and functionality, ongoing customization, and complete control.
The PaaS-based architecture provides a much higher data security capability than in-place information management systems, including industry-leading data encryption, local encryption key storage, stringent access controls, real-time audits of all platform activity, granular reporting, and a choice of storage tiers; Hot, Cool, and Archival.
Unlike SaaS archiving platforms with limited information management capabilities and one-size-fits-all security, the Archive2Azure PaaS solution is implemented in a Zero Trust model so that you move and store your company's data in your Azure tenancy with complete control over granular retention/disposition and security capabilities.
Bill Tolson is the Vice President of Global Compliance for Archive360. Managed and Professional Services provider Insentra distributes Archive360’s Archive2Azure platform exclusively across A/NZ.
